虚拟机+Ubuntu,搭建hadoop集群
一些说明和资源
虚拟机:VirtualBox-6.1.18
Ubuntu:16.04桌面版
JDK:jdk-8u281-linux-x64.tar.gz
hadoop:hadoop2.7.3
可能用到的资源:hadoop-instead
安装虚拟机和Ubuntu16.04
传送门:下载及安装教程
稍有不同的地方:
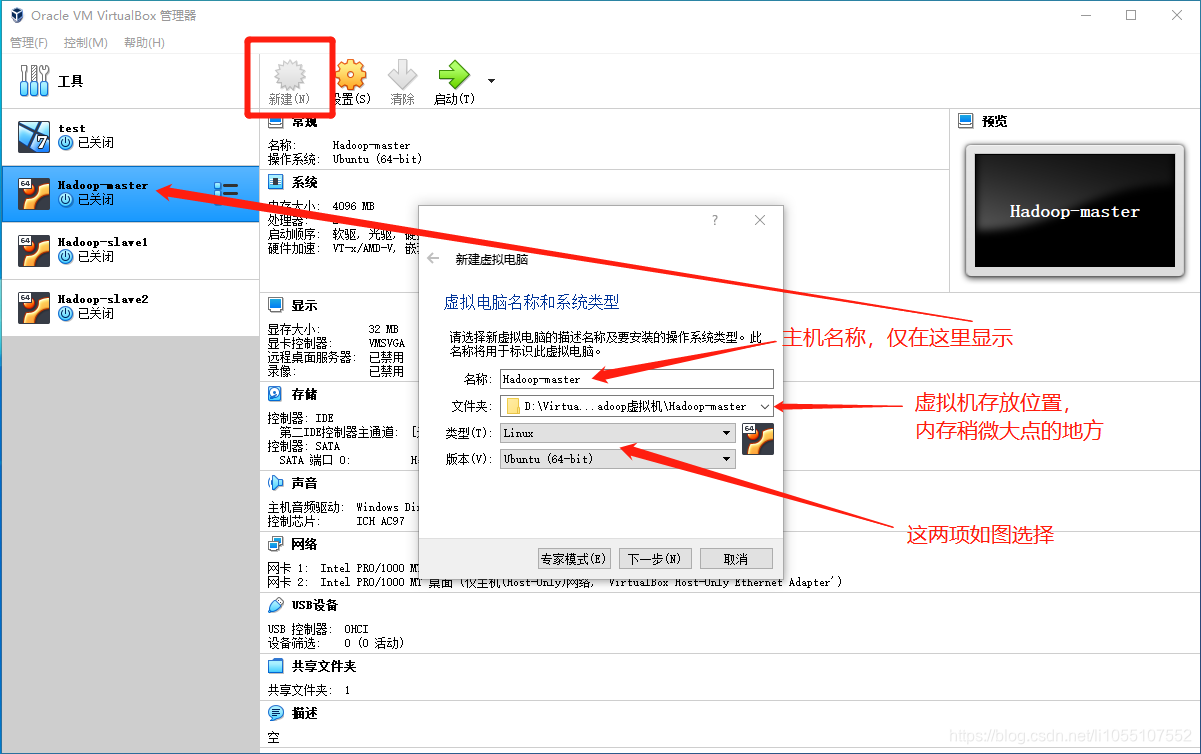
安装hadoop
1. 配置虚拟机网卡
1. 打开VirtualBox
2. 点击右上角 管理 --> 主机网络管理器 --> 创建网卡

2. 配置主机网卡
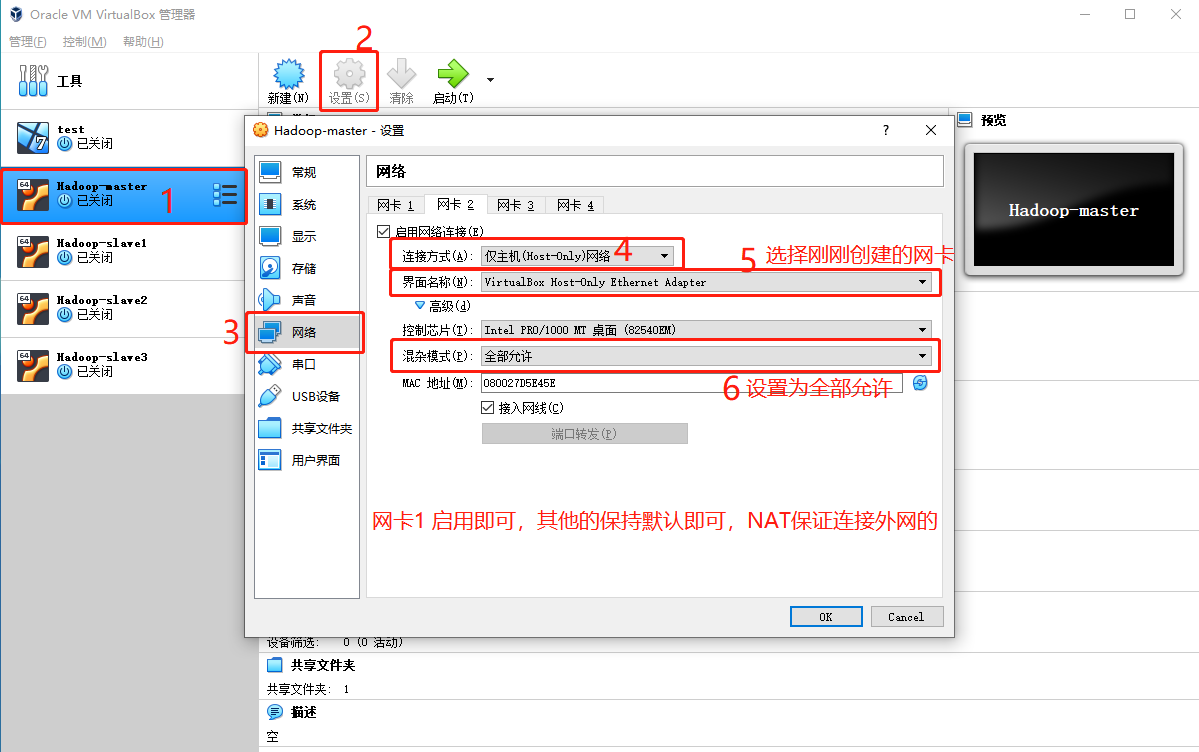
3.进入到Ubuntu
以下操作在 hadoop-master 下完成
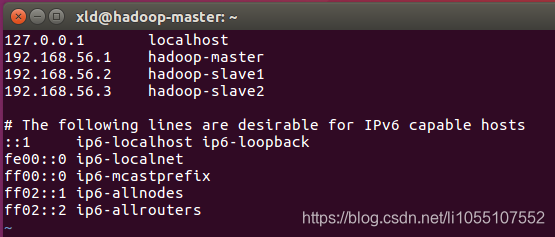
3.1 配置hosts文件
1 | $ sudo vim /etc/hosts |
// 配置如下,后面的ipv6部分无需更改:
3.2 下载和配置Java
JDK下载:官方下载地址
本地下载:jdk-8u281-linux-x64.tar.gz
1 | // 进入到jdk的存放位置 解压 |
接着配置环境变量
1 | $ sudo vim /etc/profile |
在 profile 中添加以下内容:
export JAVA_HOME=/usr/java
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export JRE_HOME=$JAVA_HOME/jre
# 下面是 后面hadoop的环境变量
# export HADOOP_HOME=/usr/hadoop
# export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
# export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
# export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后是保存 并使profile文件立即生效:
1 | $ source /etc/profile |
接着可以输入以下命令查看是否安装成功:
$ java -version
若能成功打印版本信息则为成功。
3.3 下载和配置Hadoop
官方地址:传送门
一步到位:hadoop-2.7.3.tar.gz
整体的布局:
NameNode:hadoop-master
DataNode:hadoop-master、hadoop-slave1、hadoop-slave2
ResourceManager:hadoop-master
NodeManager:hadoop-master
1 | // 进入到目录下解压 |
配置环境变量
1 | // 把上面刚刚Java的环境变量 hadoop部分注释去掉即可 |
接下来需要更改几个文件的内容:

注:mapred-site.xml 没有此文件,将mapred-site.xml.template复制一份改即可
1 | // hadoop-env.sh 将java的目录改为绝对路径,以免启动hadoop时找不到Java目录而报错 |
1 | 故意写在后面: |
配置好之后,保存并关闭该主机 hadoop-master 。
复制另外两台主机,分别名为hadoop-slave1、hadoop-slave2
复制好之后,启动三台主机。
3.4 分别更改三台主机的网络配置
3.4.1 hadoop-master
1 | $ ifconfig -a |
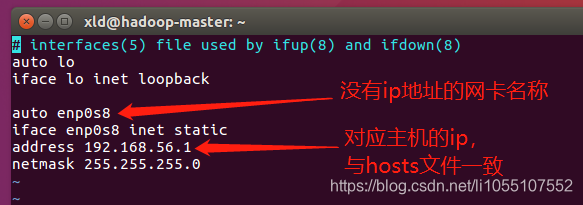
应该能看到一个网卡是没有ip地址的,那就是需要配置的。(如:enp0s8)
1 | $ sudo vim /etc/network/interfaces |
在后面添加以下内容:
1 | auto enp0s8 |
// /etc/network/interfaces:
开启网卡
1 | $ sudo ifup enp0s8 |
开启后,再次查看状态,应该是有ip地址的,如192.168.56.1
3.4.2 hadoop-slave1、hadoop-slave2
更改一下设备名称,不然host不认…

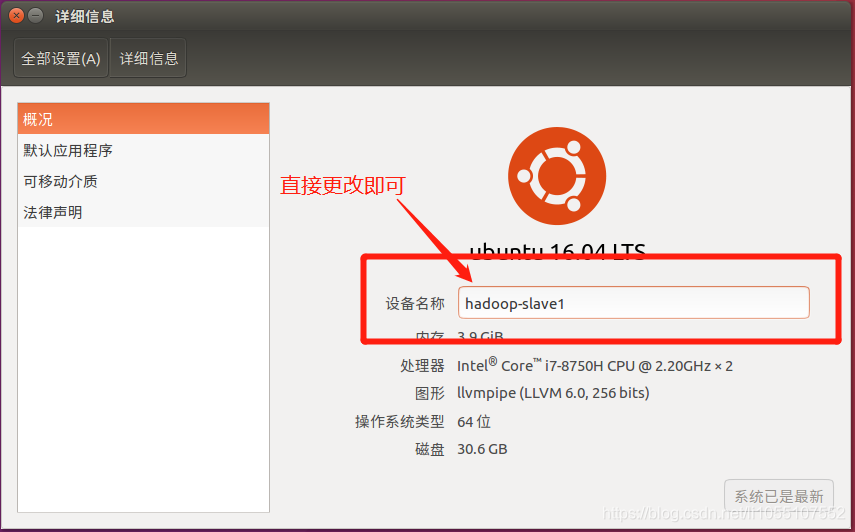
其他操作与 3.4.1 同理。
配置好之后,三台主机之间,应该是可以成功ping通的。
3.5 配置SSH免密登录
1 | // 若没有安装ssh的可以先下载更新一下(所有主机都要) |
回到我们的 hadoop-master 主机上
1 | $ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa |
注:链接时提示输入密码,是需要链接的主机的密码,不是本机的密码。
连接后,若想要退出链接,可以执行 $exit
启动hadoop
三台主机都开启后,在 master主机 上执行指令,格式化HDFS文件系统:
1 | $ hdfs namenode -format |
在master节点启动hadoop集群
1 | $ start-all.sh |
然后可以通过$ jps 查看信息,各主机的信息 应该与上文中 3.3 的整体的布局相一致
1 | 还可以通过以下命令查看hadoop集群系统的状态: |
启动程序
先跑个demo,算个π
1 | $ hadoop jar /usr/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 10 |
第一次执行,时间会较长,可能需要2-5分钟
1 | // 试过一次好像启动的时候报错了,说要把这个关掉,先写在这吧: |
其他:(我在另一本书上看到的,大家也可以拿来试着跑一下)
日志分析:
github:https://github.com/bdintro/bdintro.git
编译源代码采用mvn package,测试数据为hadoop-user-datanode-dell119.log.zip
在测试前先把对应数据上传到HDFS集群中,把使用mvn package编译好的jar包1
2
3
4
5// 上传日志到hadoop
$ hadoop fs -copyFromLocal hadoop-yangyaru-datanode-dell119.log /
// 启动
$ hadoop jar 打包好的jar包路径/bigdata-0.0.1.jar bigdata.bigdaba.Grep WARN 需分析的日志路径/hadoop-user-datanode-dell119.log 结果输出的路径/output交通流量分析:
github:https://github.com/bdintro/bdintro.git
详细的交通流量数据格式描述如网站所述:https://www.kaggle.com/jana36/us-traffic-violations-montgomery-county-poliet
编译源代码采用mvn package,测试数据为Traffic_Violations.csv.zip
在测试前先把对应数据上传到HDFS集群中,把使用mvn package编译好的jar包1
2
3
4
5// 上传交通记录到hadoop
$ hadoop fs -copyFromLocal Traffic_Violations.csv /
// 启动
$ hadoop jar 打包好的jar包路径/bigdata-0.0.1.jar bigdata.bigdaba.TrafficTotal WARN 需分析的日志路径/Traffic_Violations.csv 结果输出的路径/output
完
 微信
微信- 支付宝






